
Introduction:
When you use Python's Pandas to open a sizable Dataset and attempt to get a few metrics, everything just abruptly stops. If you frequently work with Big Data, you're undoubtedly already aware that using Pandas, a straightforward series-loading operation for a few million rows can take up to a minute! Parallel computing is the term/technique used in the industry for this. In this post, we will talk about parallel computing and the Dask library, which is recommended for such jobs. We will also cover all the different features that Dask brings to the table as well as its limitations. But let’s first start by understanding Parallel Computing.
Parallel Computing
The process of running numerous processors an application or computation simultaneously is referred to as parallel computing. In general, it refers to a type of computing architecture where big issues are divided into separate, smaller, typically related sections that can be processed all at once. Multiple CPUs work together to complete it by exchanging information across shared memory, which then combines the findings. It facilitates the execution of complex computations by distributing the enormous problem among multiple processors.
By boosting the systems' available computational capability, parallel computing also facilitates quicker application processing and task resolution. The majority of supercomputers run on parallel computing concepts. In general, parallel processing is employed in operational scenarios that require a lot of computing or processing capacity.
Why Dask?
Data manipulation and machine learning tasks are made simple with the help of Python libraries like Numpy, Pandas, Sklearn, Seaborn, and others. For the majority of data analysis tasks, the Python [pandas] module is enough. Data can be manipulated in many different ways, and machine learning models can be created using that data.
Pandas will, however, become insufficient if your data grows greater than the RAM that is available. This is a rather common problem. You can employ Spark or Hadoop to get around this. However, these aren't Python environments. You are unable to use NumPy, sklearn, pandas, TensorFlow, and other well-known Python machine-learning packages as a result. Exists a way to get around this? Yes! This is where Dask comes into play.
What is Dask?
![]()
Dataframes, Bags, and Arrays are the three parallel collections available in Dask. because of which it can store data that is bigger than RAM. Each of them can make use of data that has been divided between RAM and a hard disc or that has been dispersed among several cluster nodes. For efficiency, a Dask DataFrame has partitioned row-by-row, grouping rows by the index value. These Pandas objects could reside on a system or disc. Numerous Pandas DataFrames or Series are organized along with the index, and Dask DataFrames coordinate them.
In other words, Dask utilizes all of the cores of the connected workstations, allowing it to process data effectively on a cluster of computers. It's amazing that not every system needs to have the same amount of cores. Dask can accept the discrepancy in core count if one machine has two cores and the other has four.
Dask has two families of task schedulers:
- Basic thread pool or local process functionality is offered by a single-machine scheduler. The default scheduler was the first to be developed. It is easy to use and reasonably priced. It does not scale and is only compatible with one machine.
- A more sophisticated scheduler is the distributed scheduler. Although it requires a little more setup work, it has additional features. It can be deployed across a cluster of machines or run on a single system.
Dask highlights the following qualities:
- Familiar: Parallelized NumPy array and Pandas DataFrame objects are familiar
- Flexible: Provides a task scheduling interface to support the integration of projects and more specialized workloads.
- Native: Allows for distributed Python computation and access to the PyData stack.
- Fast: Has low overhead, low latency, and low serialization, all of which are necessary for quick numerical computations.
- Scalable: Reliable performance on clusters with tens of thousands of cores.
- Scales down: Easy to set up and run on a laptop in a single process.
- Responsive: It is responsive because it was made with interactive computing in mind and provides prompt feedback and diagnostics to benefit people.
Installation:
Type the following command in the terminal to install this module:
python -m pip install "dask[complete]"
Demonstration:
Importing the libraries:

Code to figure out the amount of time and file size:
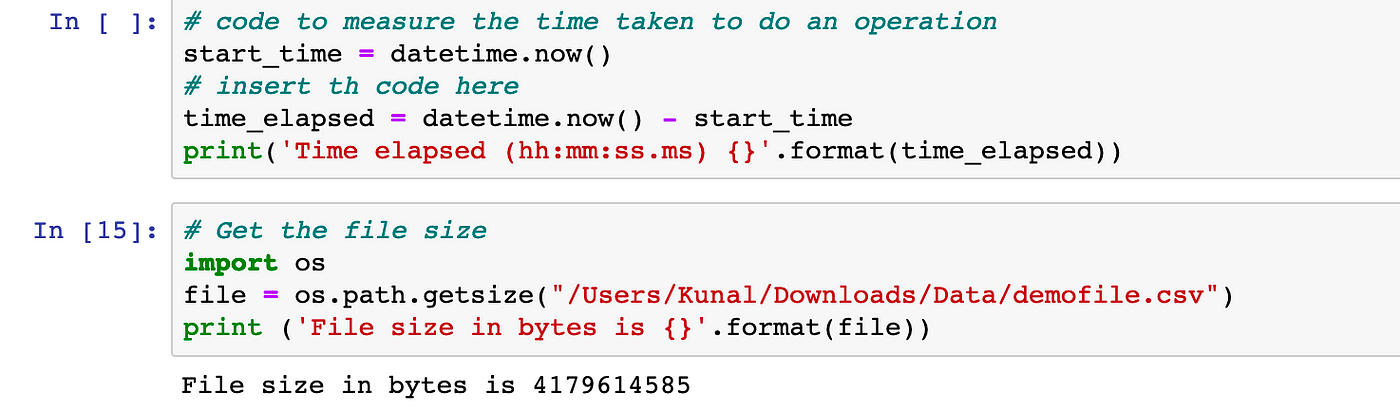
The first snippet determines the amount of time that has passed since we last performed an operation, such as reading a file. The file size that we'll be using for this demo is shown in the second snippet. The file is about 4GB in size.
Dask over Pandas:
Reading a file — Pandas & Dask:

A 4GB file took Pandas about 5 minutes to read. Wait, size isn't everything; a data set's number of columns and rows also has a significant impact on how long it takes to process. Let's check how long Dask needs to process the identical file.

Holy smokes, Pandas took about 5 minutes to read the identical file, whereas it only took a few milliseconds. Isn't it wonderful? Let's carry out a few additional operations on the dask and pandas data frames, respectively.
Appending two files — Pandas & Dask:

The foregoing operations took about 9 minutes to complete. Let's now see how Dask can be used to improve it.
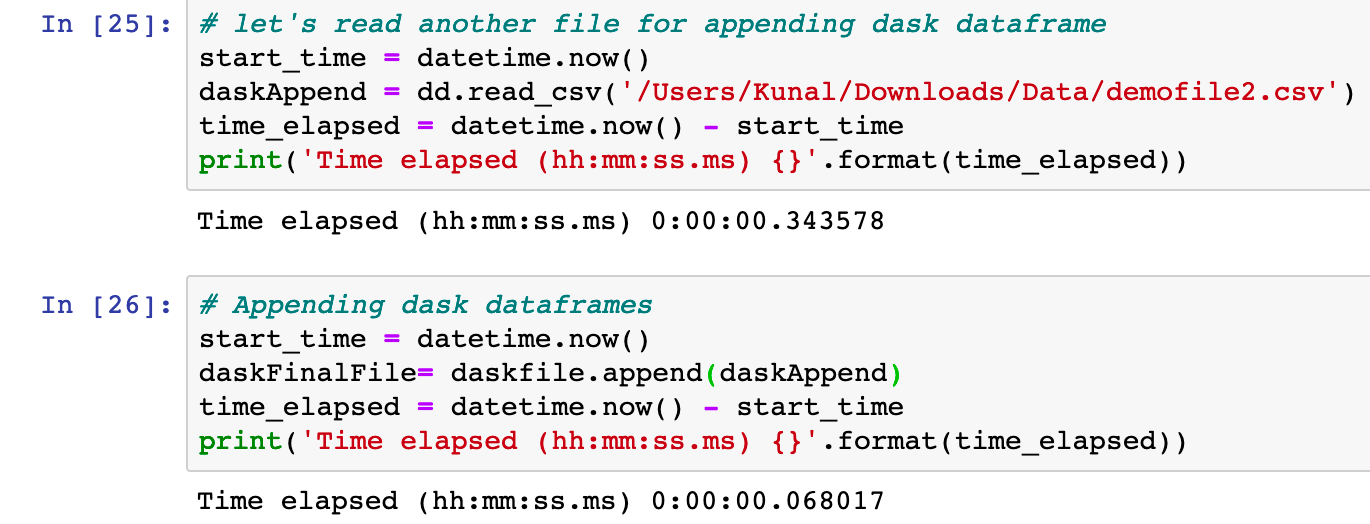
Well, you just saved yourself another nine minutes or so. Now let's look at some additional regularly done things involving pandas.
Merging the datasets — Pandas & Dask:

It failed:
It attempted for around 30 minutes, but pandas was unable to merge those two files. See if we can use dask to accomplish it.

Well, utilizing dask, it took me hardly any time at all. Dask.dataframe.read csv just reads in a sample from the beginning of the file, as opposed to pandas.read csv, which reads in the full file before inferring data types (or first file if using a glob). When reading all partitions, these assumed data types are then enforced.
Saving a Dataframe to a file — Pandas & Dask:

The file is successfully saved by Pandas. I needed around three minutes to save the filtered file.

Dask Output :
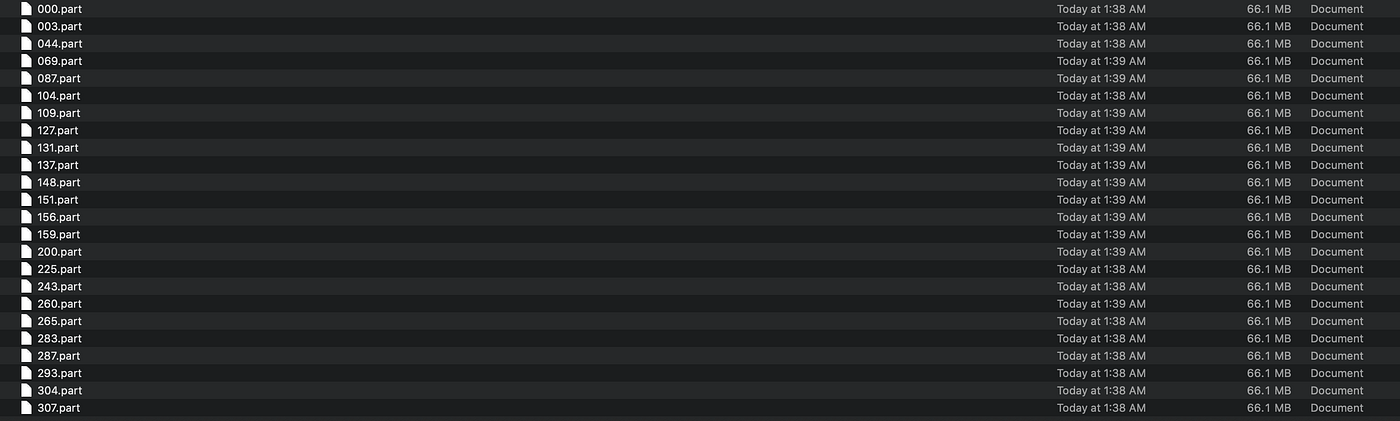
The file is not correctly saved by Dask. It divides the file into many pieces and stores these files in the aforementioned folder. Another issue is that you will never again be able to read this stored file. It is only a time-waster.
A dask data frame can be saved to a file by first being converted into a pandas data frame using this method, and then the pandas data frame is saved to a file.
Limitations
- The central scheduler spends a few hundred microseconds on every task. For optimal performance, task durations should be greater than 10-100ms.
- Dask is unable to parallelize within specific jobs. The amount of each assignment should be appropriate to avoid overwhelming any one worker in particular.
- Dask uses heuristics to distribute assignments to employees. Though it normally chooses wisely, occasionally unfortunate circumstances do arise.
- The workers are merely Python processes, thus they share all of Python's strengths and weaknesses. They are not constrained or limited in any way. You might want to use containers to run dask-workers in production.
- Dask allows for the remote execution of any code as a distributed computing platform. Only host dask-workers in networks that you are confident in. Although distributed computing frameworks all agree on this, it is nonetheless important to mention.
Conclusion:
Using Pandas and Dask together is always the ideal choice because one can effectively address the constraints of the other. When utilised separately, I guess you can encounter various problems. Thus, we draw the conclusion that using Pandas with Dask can help you save a lot of time and money.



0 Comments